本文最后更新于:2022年5月31日 下午
概览 :LeetCode刷题。
1 2 3 4 <details > <summary > 折叠/查看代码</summary > </details >
剑指 数组中只出现1次的数 | 祖龙面试
折叠/查看代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 int main () vector <int > nums = { 1 ,2 ,3 ,1 ,2 ,3 ,4 ,5 ,6 ,7 ,7 ,6 ,5 };int result = nums[0 ];int len = nums.size();for (int i = 1 ; i < len; i++) {cout << result << endl ;return 0 ;
23 合并K个升序链表
2021/04/16
给你一个链表数组,每个链表都已经按升序排列。
请你将所有链表合并到一个升序链表中,返回合并后的链表。
示例 1:
输入:lists = [[1,4,5],[1,3,4],[2,6]]
输入:lists = []
输入:lists = [[]]
来源:力扣(LeetCode)https://leetcode-cn.com/problems/merge-k-sorted-lists
思路1:采用两两归并的思想,逐步归并到一起。
思路2:获取链表的全部元素,排序成数组,然后构建链表
思路3:优先级队列 ,每次选择所有链表中元素最小的那个,直到合并完毕!
可以采用优先级队列,都暂时存放一系列链表中的第一个数,排序出其中最小的那个元素.
当将那个元素加入链表后,就将原来元素的下一个链表插入到队列中.
折叠/查看代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 class Solution {public :struct Status {int val;int vval,ListNode* vptr){bool operator <(const Status &other) const {return val>other.val;priority_queue <Status> que;ListNode* mergeKLists (vector <ListNode*>& lists) {int len = lists.size();if (len == 0 ) return nullptr ;else if (len == 1 ) return lists[0 ];for (auto i : lists){if (i != nullptr ){new ListNode();while (!que.empty()){if (i.ptr->next != nullptr ) que.push({i.ptr->next->val,i.ptr->next});return nodes->next;
53 最大子序和 | 祖龙面试
2021/04/18
给定一个整数数组 nums ,找到一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
示例 1:
输入:nums = [-2,1,-3,4,-1,2,1,-5,4]
输入:nums = [1]
输入:nums = [0]
输入:nums = [-1]
输入:nums = [-100000]
提示:
1 <= nums.length <= 3 * 104
来源:力扣(LeetCode)https://leetcode-cn.com/problems/maximum-subarray
面试时的写法 面试时想到了动态规划,然后使用了二维的动态规划数组。最后勉强做出来了,但是面试官很不满意。
折叠/查看代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 int maxSubArray (vector <int >& nums) int len = nums.size();if (len == 1 )return nums[0 ];vector <vector <int >> dp(len,vector <int >(len));int maxsum = -100001 ;for (int i=0 ;i<len;i++){for (int j = i+1 ;j<len;j++){-1 ]+nums[j],nums[j]);return maxsum;
动态规划优化 只需要找到最大值,使用一位的dp数组,就可以解决这个问题,dp[i]存储的是0-i上的最大子序列的和。
折叠/查看代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 int maxSubArray (vector <int >& nums) int len = nums.size();if (len == 1 )return nums[0 ];vector <int > dp (len) int maxsum = nums[0 ];0 ] = nums[0 ];for (int i=1 ;i<len;i++){-1 ]+nums[i]);return maxsum;
动态规划再优化 将上述dp[i]的思想再进行优化,使用O(1)的空间 ,使用一个变量去保存之前的最大值即可。
折叠/查看代码
1 2 3 4 5 6 7 8 9 10 11 12 int maxSubArray (vector <int >& nums) int len = nums.size();int sum = nums[0 ];int maxsum = nums[0 ];for (int i=1 ;i<len;i++){return maxsum;
剑指 旋转数组的最小数字
2021/04/18
把一个数组最开始的若干个元素搬到数组的末尾,我们称之为数组的旋转。输入一个递增排序的数组的一个旋转,输出旋转数组的最小元素。例如,数组 [3,4,5,1,2] 为 [1,2,3,4,5] 的一个旋转,该数组的最小值为1。
示例 1:
输入:[3,4,5,1,2]
输入:[2,2,2,0,1]
来源:力扣(LeetCode)https://leetcode-cn.com/problems/xuan-zhuan-shu-zu-de-zui-xiao-shu-zi-lcof
思路1:直接遍历 找寻非单调递减序列发生变化的地方,那就是最小值!时间 O(n).
折叠/查看代码
1 2 3 4 5 6 7 8 9 10 11 12 13 int minArray1 (vector <int >& numbers) int ans = numbers[0 ];int len = numbers.size();for (int i=0 ;i<len;i++){if (ans <= numbers[i])continue ;else return numbers[i];return ans;
思路2:二分查找 若中间的元素,小于最后一个元素,按照题意,可知这后半段是完全递增的,所以最小值在前半段。
若中间元素,大于最后一个元素,则最小值就在后半段。
若中间元素等于最后一个元素:
对于这些情况,可以更改right的指针来缩减范围 ,即right指针所指位置,肯定不会是最小元素(元素完全相同不考虑)。
不能更改left,left可能会指向最小值!
时间:O(log n)
折叠/查看代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 int minArray (vector <int >& numbers) int len = numbers.size();int left = 0 ;int right = len-1 ;while (left < right){int mid = left + (right-left)/2 ;if (numbers[mid] > numbers[right])1 ;else if (numbers[mid] < numbers[right])else return numbers[left];
剑指 二叉搜索树转双向链表 | 好未来二面
2021/04/18
输入一棵二叉搜索树,将该二叉搜索树转换成一个排序的循环双向链表。要求不能创建任何新的节点,只能调整树中节点指针的指向。
为了让您更好地理解问题,以下面的二叉搜索树为例:
我们希望将这个二叉搜索树转化为双向循环链表。链表中的每个节点都有一个前驱和后继指针。对于双向循环链表,第一个节点的前驱是最后一个节点,最后一个节点的后继是第一个节点。
下图展示了上面的二叉搜索树转化成的链表。“head” 表示指向链表中有最小元素的节点。
特别地,我们希望可以就地完成转换操作。当转化完成以后,树中节点的左指针需要指向前驱,树中节点的右指针需要指向后继。还需要返回链表中的第一个节点的指针。
来源:力扣(LeetCode)https://leetcode-cn.com/problems/er-cha-sou-suo-shu-yu-shuang-xiang-lian-biao-lcof
思路:二叉搜索树,中序遍历是一个递增序列。可通过中序遍历过程中,修改前面节点的指针指向。
当然对头尾两个节点的指针要额外处理,达到双向循环链表的效果。
折叠/查看代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 class Solution {public :Node* treeToDoublyList (Node* root) {if (root == NULL ) return NULL ;stack <Node *> st;NULL ;while (tmp != NULL || !st.empty()) {if (tmp != NULL ) {else {if (pre == NULL ) {else { return head;
131 分割回文串
2021/04/18
给你一个字符串 s,请你将 s 分割成一些子串,使每个子串都是 回文串 。返回 s 所有可能的分割方案。
回文串 是正着读和反着读都一样的字符串。
示例 1:
输入:s = “aab”
输入:s = “a”
提示:
1 <= s.length <= 16
来源:力扣(LeetCode)https://leetcode-cn.com/problems/palindrome-partitioning
回溯算法
视频讲解:https://www.bilibili.com/video/BV1c54y1e7k6
折叠/查看代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 class Solution {public :vector <vector <string >> result;vector <string > path;bool isParl (string & s) int len = s.size();if (len <= 1 ) return true ;int i = 0 ;int j = len-1 ;while (i <= j){if (s[i] == s[j]){else return false ;return true ;void trackback (string &s, int start) if (start >= s.size()){return ;for (int i = start;i<s.size();i++){string tmp = s.substr(start,i-start+1 );if (isParl(tmp)){1 );else {continue ;vector <vector <string >> partition(string s) {0 );return result;
剑指 数据流中的中位数
2021/04/19
如何得到一个数据流中的中位数?如果从数据流中读出奇数个数值,那么中位数就是所有数值排序之后位于中间的数值。如果从数据流中读出偶数个数值,那么中位数就是所有数值排序之后中间两个数的平均值。
例如,
[2,3,4] 的中位数是 3
[2,3] 的中位数是 (2 + 3) / 2 = 2.5
设计一个支持以下两种操作的数据结构:
void addNum(int num) - 从数据流中添加一个整数到数据结构中。
输入:
输入:
来源:力扣(LeetCode)https://leetcode-cn.com/problems/shu-ju-liu-zhong-de-zhong-wei-shu-lcof
思路1:排序,然后找到中位数,但是对于这种数据流不断增加的数组来说,每次都需要重新排序,每次O(nlog n).
思路2:使用堆排序,构建两个数量几乎相同的堆,一个小顶堆一个大顶堆,小顶堆的全部元素都大于等于大顶堆的堆顶元素。这样数据的中位数都在两个堆顶之间产生。而每次调整堆的时间复杂度是O(logn),每次至多调整两个堆,这样的时间复杂度仍然小于排序的。
折叠/查看代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 class MedianFinder {public :vector <int > min;vector <int > max;void addNum (int data) if (min.size() > max.size()) {if (data > min[0 ]) {int >());int tmp = min.back();int >());int >());else {if (min.size() == 0 ) {int >());else {int >());int >());int tmp = max.back();int >());double findMedian () if (((min.size() + max.size()) & 1 ) == 1 ) {return min[0 ];else {return (min[0 ] + max[0 ]) / 2.0 ;
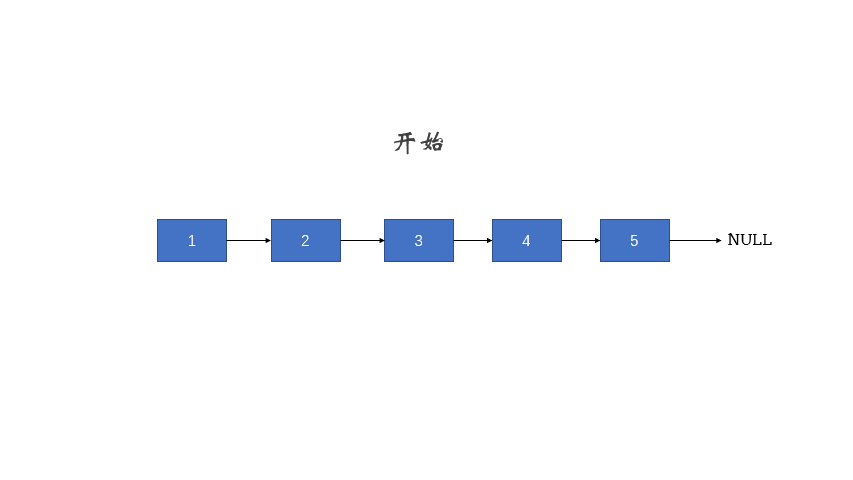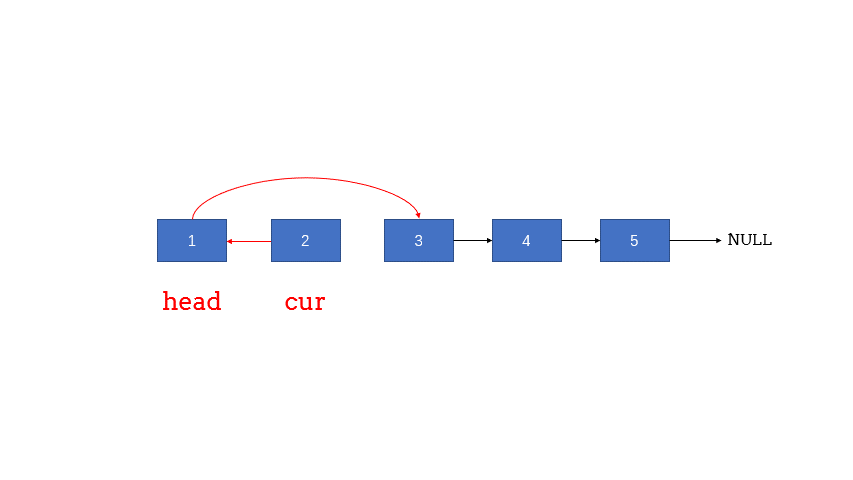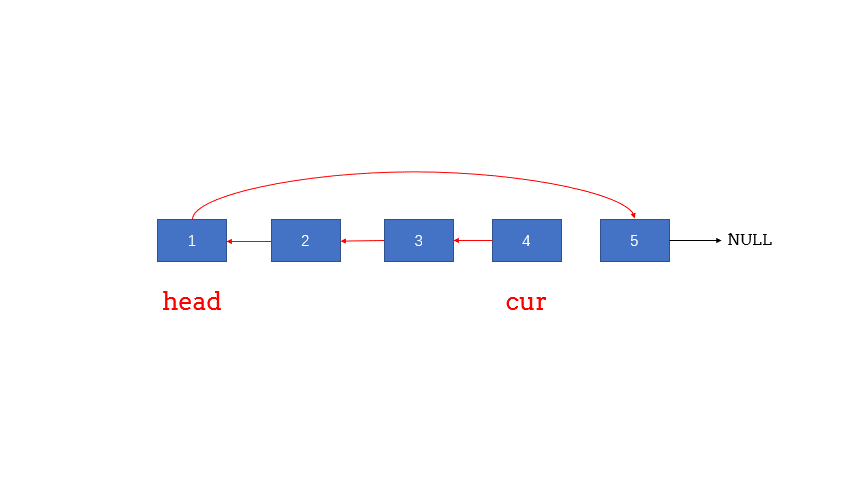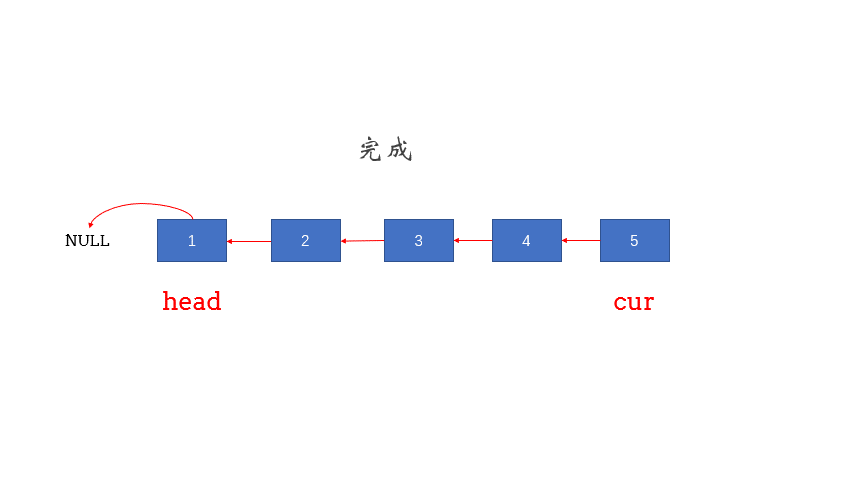
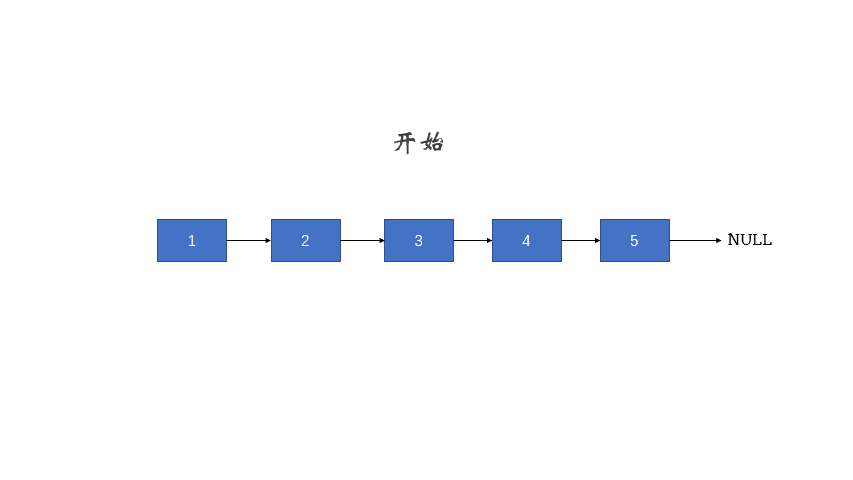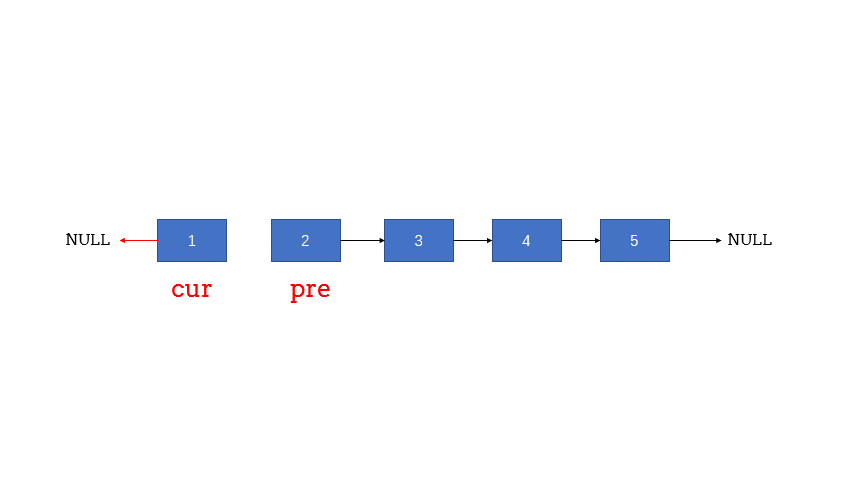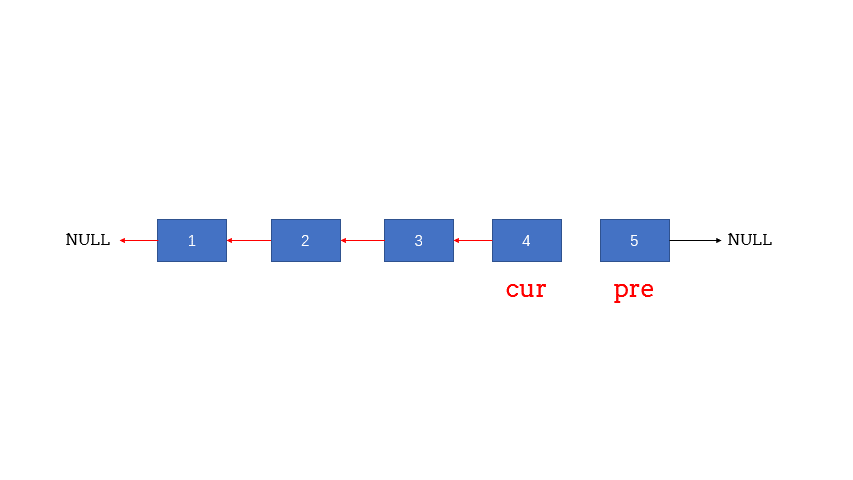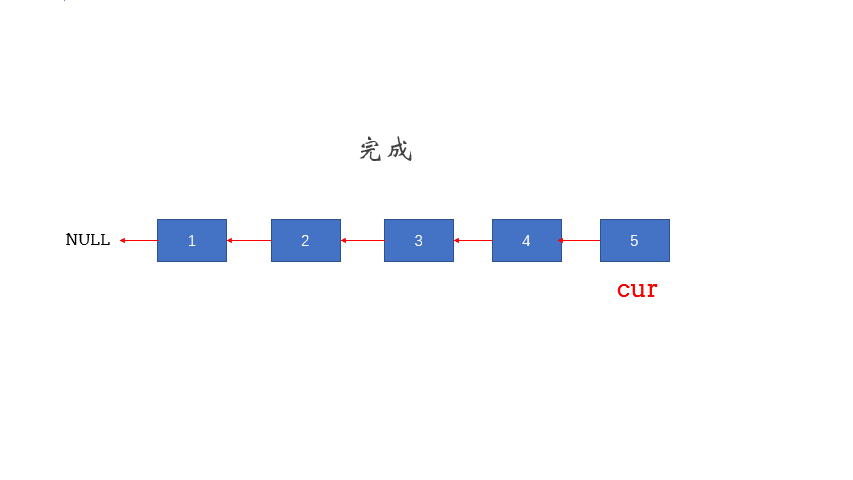
206 翻转链表
2021/04/21
反转一个单链表。
示例:
输入: 1->2->3->4->5->NULL
来源:力扣(LeetCode)https://leetcode-cn.com/problems/reverse-linked-list
迭代式
图片来源:https://leetcode-cn.com/problems/reverse-linked-list/solution/fan-zhuan-lian-biao-shuang-zhi-zhen-di-gui-yao-mo-/
折叠/查看代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class Solution {public :ListNode* reverseList (ListNode* head) {if (head == nullptr || head->next == nullptr ) return head;new ListNode(0 ,head);nullptr ;while (cur != nullptr ){return prehead->next;
递归式
递归的找到最后一个节点,返回,中间不对那个节点做任何处理,单纯的返回,这样就成了第一个节点。
head表示每个递归中的当前的那个节点,使得其后一个节点指向它,然后它在指向Null.
图片来源:https://leetcode-cn.com/problems/reverse-linked-list/solution/fan-zhuan-lian-biao-shuang-zhi-zhen-di-gui-yao-mo-/
折叠/查看代码
1 2 3 4 5 6 7 8 9 10 11 12 ListNode* reverseList (ListNode* head) {if (head == nullptr || head->next == nullptr ) return head;nullptr ;return ret;
双指针 思想就是:fast指针指向low指针,局部反转,直到fast走到了末尾。
图片来源:https://leetcode-cn.com/problems/reverse-linked-list/solution/fan-zhuan-lian-biao-shuang-zhi-zhen-di-gui-yao-mo-/
折叠/查看代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 ListNode* reverseList (ListNode* head) {if (head == nullptr || head->next == nullptr ) return head;nullptr ;while (fast != nullptr ){return low;
617 合并二叉树
2021/04/21
给定两个二叉树,想象当你将它们中的一个覆盖到另一个上时,两个二叉树的一些节点便会重叠。
你需要将他们合并为一个新的二叉树。合并的规则是如果两个节点重叠,那么将他们的值相加作为节点合并后的新值,否则不为 NULL 的节点将直接作为新二叉树的节点。
示例 1:
输入:
来源:力扣(LeetCode)https://leetcode-cn.com/problems/merge-two-binary-trees
递归
折叠/查看代码
1 2 3 4 5 6 7 8 9 10 TreeNode *mergeTrees (TreeNode *root1,TreeNode * root2) {if (root1 == nullptr || root2 == nullptr ){return root1 == nullptr ? root2:root1;return root1;
或者使用广度优先遍历的思想实现,使用两个辅助队列。
剑指 二叉搜索树的最近公共祖先
2021/04/21
给定一个二叉搜索树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
例如,给定如下二叉搜索树: root = [6,2,8,0,4,7,9,null,null,3,5]
示例 1:
输入: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 8
输入: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 4
说明:
所有节点的值都是唯一的。
来源:力扣(LeetCode)https://leetcode-cn.com/problems/er-cha-sou-suo-shu-de-zui-jin-gong-gong-zu-xian-lcof
因为是二叉搜索树,所以找到节点的同时,走过的路径就是其对应的祖先节点。
获得全部的祖先节点之后,从后向前找到两个路径中都有的。
vector没有提供find方法,使用算法头文件的方法即可。
折叠/查看代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 TreeNode* lowestCommonAncestor (TreeNode* root, TreeNode* p, TreeNode* q) {vector <TreeNode *>path1;vector <TreeNode*> path2;while (tmp != p){if (tmp->val > p->val){else {while (tmp != q){if (tmp->val > q->val){else {for (auto it = path1.rbegin();it!= path1.rend();it++){auto result = find(path2.begin(),path2.end(),*it);if (result != path2.end()){return *it;return nullptr ;
另一种思路,巧妙运用二叉搜索树的特性,若当前节点均大于两个节点,当前节点向左,若均小于两个节点,向右。
其他情况下,一大一小,就是中间节点 。
这样一次遍历,而且不用去对比和查找。