Kafka生产者与消费者
本文最后更新于:2022年7月5日 凌晨
概览:Kafka
预警!仅用于本人快速自学,不过欢迎指正。
Kafka生产者
发送消息
在消息发送的过程中,涉及到了两个线程——main 线程和 Sender 线程。
在 main 线程中创建了一个双端队列 RecordAccumulator。
- RecordAccumulator 缓冲区总大小,默认 32m。
- batch.size:缓冲区一批数据最大值,默认 16k。适当增加该值,可以提高吞吐量
- linger.ms:如果数据迟迟未达到 batch.size,sender 等待 linger.time之后就会发送数据。单位 ms,默认值是 0ms,表示没
有延迟。生产环境建议该值大小为 5-100ms 之间
main 线程将消息发送给 RecordAccumulator,Sender 线程不断从 RecordAccumulator 中拉取消息发送到 Kafka Broker。

- 如果消息发送失败会自动重试,不需要人为干扰。
- acks:
- 0:生产者发送过来的数据,不需要等数据落盘应答。
- 1:生产者发送过来的数据,Leader 收到数据后应答。
- -1(all):生产者发送过来的数据,Leader+和 isr 队列里面的所有节点收齐数据后应答。默认值是-1,-1 和all 是等价的。
- retries:当消息发送出现错误的时候,系统会重发消息。retries
表示重试次数。默认是 int 最大值
生产者分区 partition
- 便于合理使用存储资源,每个partition在一个Broker上存储,可以把海量数据按照分区切割存储在多个Broker,合理分区可以达到负载均衡的效果。
- 提高并行度
默认分区策略:
- 指明partition的情况下,直接将指明的值作为partition值;例如partition=0,所有数据写入分区0
- 没有指明partition值但有key的情况下,将key的hash值与topic的partition数进行取余得到partition值;例如:key1的hash值=5, key2的hash值=6 ,topic的partition数=2,那么key1 对应的value1写入1号分区,key2对应的value2写入0号分区。
- 既没有partition值又没有key值的情况下,Kafka采用Sticky Partition(黏性分区器),会随机选择一个分区,并尽可能一直使用该分区,待该分区的batch已满或者已完成,Kafka再随机一个分区进行使用(和上一次的分区不同)。
自定义分区:
例如,要把一个表的数据都发送给一个分区,可以使用表名字作为key。
或者做类似过滤操作,过滤字符串。
生产者 - 提升吞吐量
- 增加批次大小batch.size
- 修改等待时长,稍微增加,linger.ms
- 压缩,compression.type
- 修改缓冲区大小,扩大缓冲区,buffer.memory
生产者 - 数据可靠性
acks机制
- 0:生产者发送过来的数据,不需要等数据落盘应答。
- 很容易丢数据,但是效率最高
- 1:生产者发送过来的数据,Leader 收到数据后应答。
- 当应答完成之后,还没开始同步副本的时候,leader节点挂掉就会丢数
- 常用于传输普通日志,允许丢失个别数据
- -1(all):生产者发送过来的数据,Leader+和 isr 队列里面的所有节点收齐数据后应答。默认值是-1,-1 和all 是等价的。
- ISR队列:这是和Leader保持同步的Follwer+Leader的集合!注意包含leader
- 如果Follwer长时间没有和Leader通信或者同步数据,就会被移除。
- 但是如果分区副本为1个,或者ISR的最小副本数量为1时,就和ack=1一样了,也会丢数。
数据完全可靠的条件:ACK = -1 + 分区副本 >= 2 + ISR队列应答的最小副本数 >= 2
生产者 - 数据去重
数据传递语义
- At Least Once:ACK级别设置为-1 + 分区副本大于等于2 + ISR里应答的最小副本数量大于等于2
- 能保证数据不丢,但不保证不重
- At Most Once:ACK级别设置为0
- 能保证数据不重,但不保证不丢
- Exactly Once
- 要求保证不丢不重,使用幂等性和事务保证
幂等性
幂等性就是指Producer不论向Broker发送多少次重复数据,Broker端都只会持久化一条,保证了不重复。
精确一次(Exactly Once) = 幂等性 + 至少一次( ack=-1 + 分区副本数>=2 + ISR最小副本数量>=2) 。
重复数据的判断标准:具有**<ProducerID, Partition, SeqNumber>**相同主键的消息提交时,Broker只会持久化一条。
其中ProducerID是Kafka每次重启都会分配一个新的;Partition 表示分区号;Sequence Number是单调自增的。
所以幂等性只能保证的是在单分区单会话内不重复。
使用:开启参数 enable.idempotence 默认为 true,false 关闭。
事务

使用事务:
- 必须开启幂等性
- 必须设置事务id,这个是开发者自定义的。
参考链接:
https://cloud.tencent.com/developer/article/1562878
生产者 - 数据有序
多分区保证有序比较困难,分区与分区之间无序。
单分区内有序:
kafka在1.x版本之前保证数据单分区有序,条件如下:max.in.flight.requests.per.connection=1(不需要考虑是否开启幂等性)。
kafka在1.x及以后版本保证数据单分区有序,条件如下:
未开启幂等性
max.in.flight.requests.per.connection需要设置为1。
开启幂等性
max.in.flight.requests.per.connection需要设置小于等于5。
原因说明:因为在kafka1.x以后,启用幂等后,kafka服务端会缓存producer发来的最近5个request的元数据,故无论如何,都可以保证最近5个request的数据都是有序的。
Broker - 副本
(1)Kafka 副本作用:提高数据可靠性。
(2)Kafka 默认副本 1 个(即leader),生产环境一般配置为 2 个,保证数据可靠性;太多副本会 增加磁盘存储空间,增加网络上数据传输,降低效率。
(3)Kafka 中副本分为:Leader 和 Follower。Kafka 生产者只会把数据发往 Leader, 然后 Follower 找 Leader 进行同步数据。
(4)Kafka 分区中的所有副本统称为 AR(Assigned Repllicas)。
消费者
消费方式
常见的消费者消费方式有两种,pull 拉,push 推
Kafka采取的是主动的pull拉的方式,主动拉取
缺点:如果kafka没有数据,消费者可能陷入循环之中,一直返回空数据。
Kafka消费者组
Consumer Group(CG):消费者组,由多个consumer组成。形成一个消费者组的条件,是所有消费者的groupid相同。
消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费。
消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
两个独立的消费者,都可以消费同一个主题的分区数据。
eg: 一个主题,4个broker(节点),每个节点一个分区
- 1个消费者,则全部消费
- 2个消费者,则前两个分区第一个消费者,后两个分区第二个消费者
- 4个消费者,每个分区一个消费者
- 5个消费者,超出主题分区数量的,消费者就会闲置,不会接受任何消息
如果向消费组中添加更多的消费者,超过主题分区数量,则有一部分消费者就会闲置,不会接收任何消息。
消费者总体工作流程
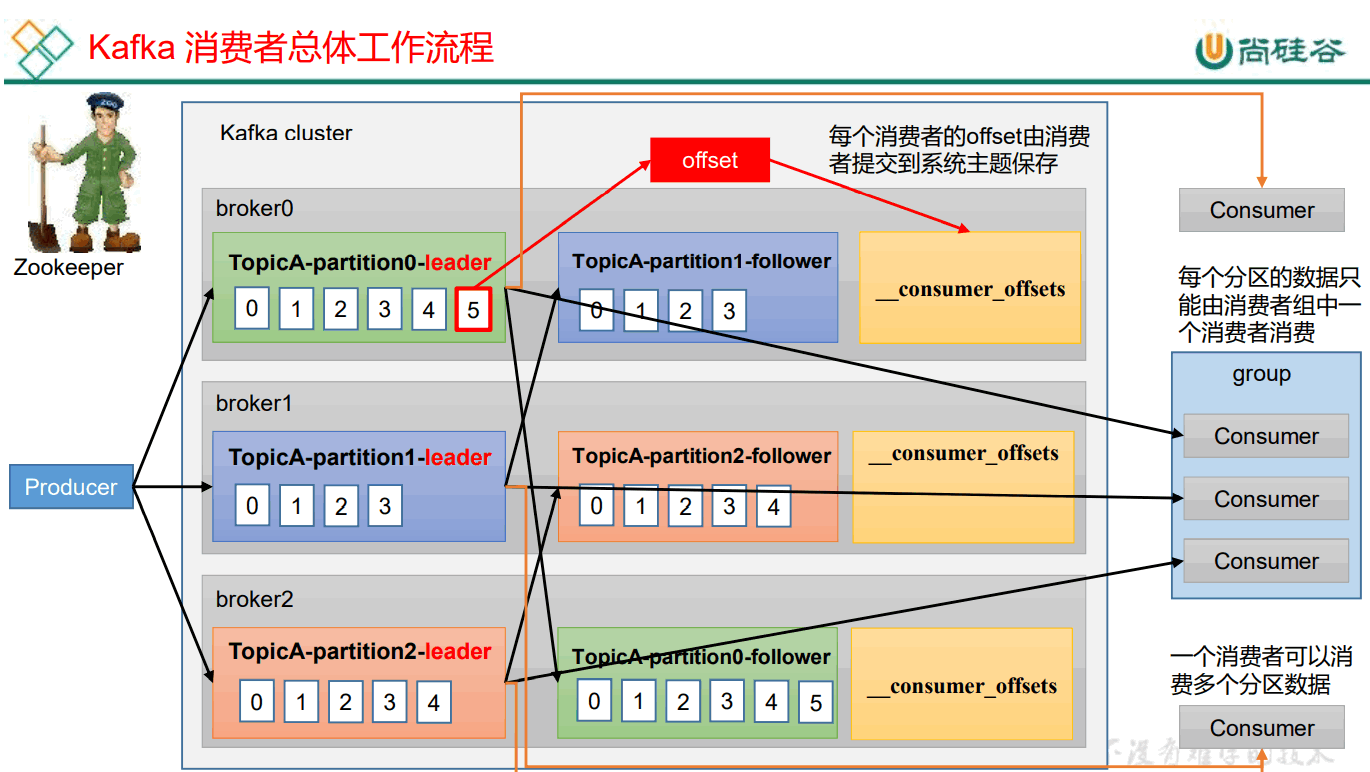
消费者组初始化
coordinator:辅助实现消费者组的初始化和分区的分配。 coordinator节点选择 = groupid的hashcode值 % 50( __consumer_offsets的分区数量) __
例如: groupid的hashcode值 = 1,1% 50 = 1,那么 consumer_offsets 主题的1号分区,在哪个broker上,就选择这个节点的coordinator 作为这个消费者组的老大。消费者组下的所有的消费者提交offset的时候就往这个分区去提交offset。
- 每个consumer都发送joinGroup请求到coordinator
- coordinator选择一个consumer作为leader
- 把要消费的topic情况发送给consumer的leader
- leader会负责只当消费方案
- leader把消费方案发给coordinator
- coordinator把消费方案下发给各个consumer
- 每个消费者会和coordinator保持心跳(默认3s),一旦超时(45s),该消费者会被移除,并且触发再平衡;或者消费者处理消息时间过长(5分钟),也会触发再平衡。
消费者组消费
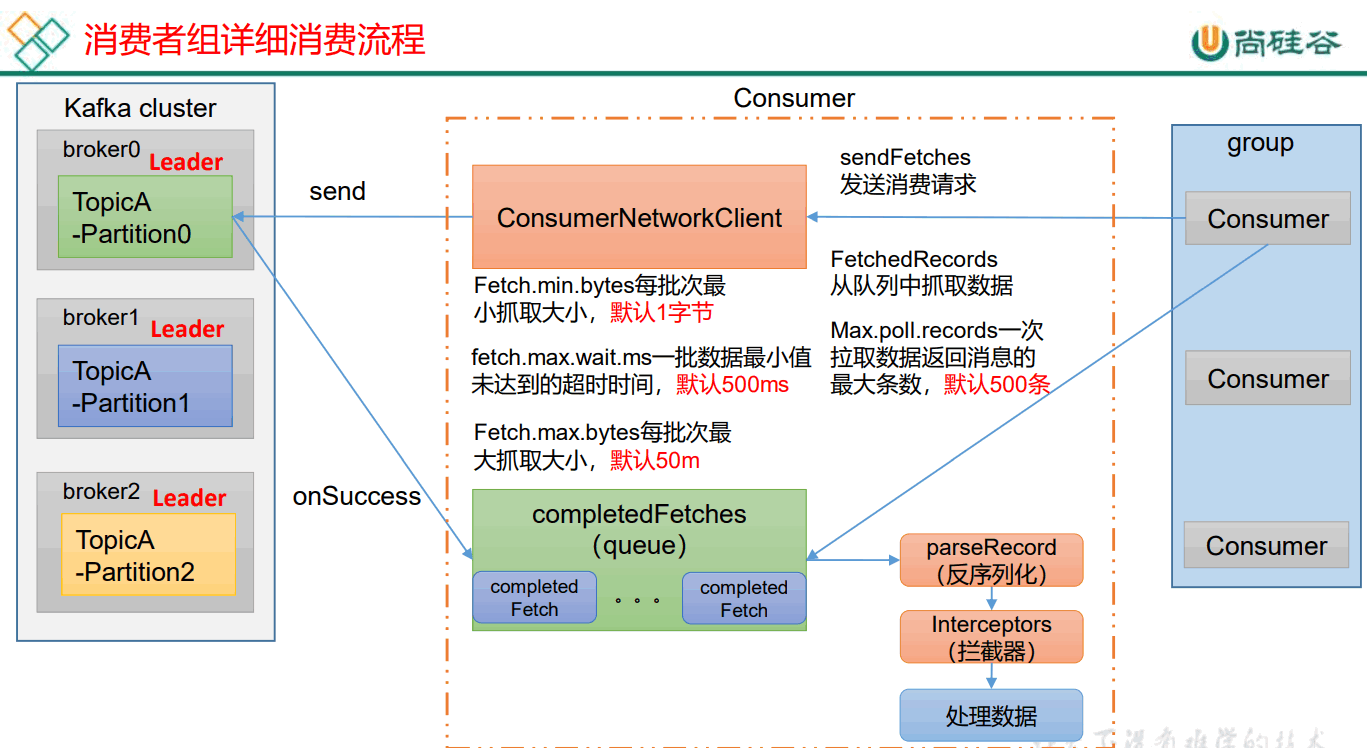
参数
- enable.auto.commit:默认值为 true,消费者会自动周期性地向服务器提交偏移量。
- auto.offset.reset:当 Kafka 中没有初始偏移量或当前偏移量在服务器中不存在(如,数据被删除了),该如何处理? earliest:自动重置偏移量到最早的偏移量。 latest:默认,自动重置偏移量为最新的偏移量。 none:如果消费组原来的(previous)偏移量不存在,则向消费者抛异常。 anything:向消费者抛异常。
分区分配 + 再平衡
Kafka 默认的分区分配策略就是 Range + CooperativeSticky
range策略
Range 是对每个 topic 而言的。
首先对同一个 topic 里面的分区按照序号进行排序,并对消费者按照字母顺序进行排序。
假如现在有 7 个分区,3 个消费者,排序后的分区将会是0,1,2,3,4,5,6;消费者排序完之后将会是C0,C1,C2。
桶过 partitions数/consumer数 来决定每个消费者应该消费几个分区。如果除不尽,那么前面几个消费者将会多消费 1 个分区。
注意:如果只是针对 1 个 topic 而言,C0消费者多消费1个分区影响不是很大。但是如果有 N 多个 topic,那么针对每个 topic,消费者 C0都将多消费 1 个分区,topic越多,C0消费的分区会比其他消费者明显多消费 N 个分区。
容易产生数据倾斜!
roundRobin策略
RoundRobin 针对集群中所有Topic而言。
RoundRobin 轮询分区策略,是把所有的 partition 和所有的consumer 都列出来,然后按照 hashcode 进行排序,最后通过轮询算法来分配 partition 给到各个消费者。
Sticky 以及再平衡
粘性分区定义:可以理解为分配的结果带有“粘性的”。即在执行一次新的分配之前,考虑上一次分配的结果,尽量少的调整分配的变动,可以节省大量的开销。
粘性分区是 Kafka 从 0.11.x 版本开始引入这种分配策略,首先会尽量均衡的放置分区到消费者上面,在出现同一消费者组内消费者出现问题的时候,会尽量保持原有分配的分区不变化。
offset
Kafka0.9版本之前, consumer默认将offset 保存在Zookeeper。
从0.9版本开始,consumer默认将offset保存在Kafka一个内置的topic中,该topic为__consumer_offsets
__consumer_offsets 主题里面采用 key 和 value 的方式存储数据。key 是 group.id+topic+分区号,value 就是当前 offset 的值。每隔一段时间,kafka 内部会对这个 topic 进行compact,也就是每个 group.id+topic+分区号就保留最新数据。
提交offset:
自动提交
手动同步提交:提交offset之后等待提交成功
手动异步提交
指定offset进行消费:
auto.offset.reset = earliest | latest | none 默认是 latest。
当 Kafka 中没有初始偏移量(消费者组第一次消费)或服务器上不再存在当前偏移量时(例如该数据已被删除),该怎么办?
(1)earliest:自动将偏移量重置为最早的偏移量,–from-beginning。
(2)latest(默认值):自动将偏移量重置为最新偏移量。
如果有偏移量的话:group.id + topic + 分区号 就能找到对应的偏移量然后开始消费。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!