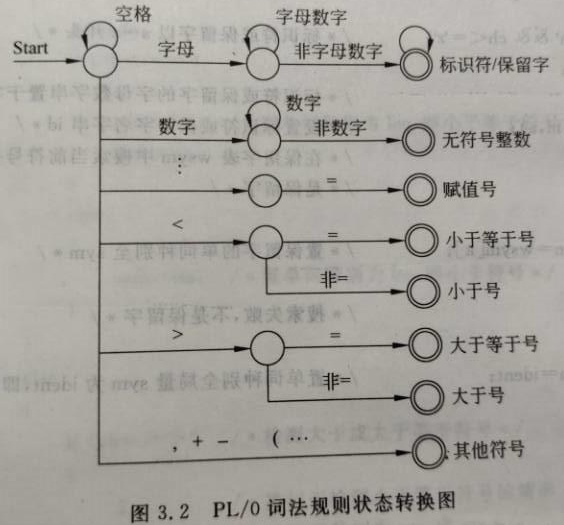
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
| #include <iostream>
#include <fstream>
#include <string>
#include <list>
#include <algorithm>
#include <conio.h>
using namespace std;
list<string> keyword_list;
list<char> operator_list;
list<char> board_list;
void init();
void getsym(string str,int index,int lines);
int printchar(char *str, int len);
void errors(int lines, int err_num,string errstr);
int main()
{
init();
ifstream readfile;
readfile.open("resourse.txt", ios::in);
string tmp;
int lines = 1;
while (getline(readfile,tmp))
{
cout <<"Lines"<<lines<<": {"<< tmp <<"}"<< endl;
getsym(tmp, 0, lines);
lines++;
cout << endl;
}
_getch();
return 0;
}
void init()
{
string keyword[13] = { "begin", "call" ,"const" ,"do" ,"end" ,"if" ,
"odd" ,"procedure" ,"read" ,"then" ,"var" ,"while" ,"write" };
keyword_list.assign(keyword,keyword+ sizeof(keyword) / sizeof(keyword[0]));
char operators[8] = {'+','-','*','/','=','#','<','>'};
operator_list.assign(operators, operators + sizeof(operators) / sizeof(operators[0]));
char boards[5] = { '(',')',',',';','.' };
board_list.assign(boards, boards + sizeof(boards) / sizeof(boards[0]));
}
void getsym(string str,int index,int lines)
{
char ch = str[index];
if (ch == '\0') return;
while (ch == ' ' || ch == '\t')
{
index++;
ch = str[index];
}
if (ch == '\0') return;
if (ch >= 'a' && ch <= 'z')
{
int word_index = 0;
char new_word[100];
new_word[word_index] = ch;
while(str[index + 1] != '\0' && (str[index + 1] >= 'a' && str[index + 1] <= 'z') || (str[index + 1] >= '0' && str[index + 1] <= '9'))
{
word_index++;
index++;
new_word[word_index] = str[index];
}
string strs = string(new_word, new_word + word_index+1);
if (find(keyword_list.begin(), keyword_list.end(), strs) != keyword_list.end())
{
cout<< "保留字 —— " << strs << endl;
}
else cout << "标识符 —— " << strs << endl;
}
else if (ch >= '0' && ch <= '9')
{
int word_index = 0;
char new_word[100];
new_word[word_index] = ch;
while (str[index + 1] != '\0' && str[index + 1] >= '0' && str[index + 1] <= '9')
{
word_index++;
index++;
new_word[word_index] = str[index];
}
if (str[index + 1] != '\0' && str[index + 1] >= 'a' && str[index + 1] <= 'z')
{
string errstr = string(new_word,new_word+word_index+1);
errstr.append(1,str[index+1]);
index++;
while (str[index + 1] != '\0' && str[index + 1] >= 'a' && str[index + 1] <= 'z')
{
errstr.append(1, str[index + 1]);
index++;
}
errors(lines, 1,errstr);
}
else
{
cout << "数字 —— ";
printchar(new_word, word_index);
cout << endl;
}
}
else if (ch == ':')
{
if (str[index + 1] == '=')
{
index++;
cout << "运算符 —— :=" << endl;
}
else if (str[index + 1] != '=')
{
string errstr = "";
errors(lines, 0,errstr);
}
}
else if (ch == '<')
{
if (str[index + 1] == '=')
{
index++;
cout << "运算符 —— <=" << endl;
}
else cout << "运算符 —— <" << endl;
}
else if (ch == '>')
{
if (str[index + 1] == '=')
{
index++;
cout << "运算符 —— >=" << endl;
}
else cout << "运算符 —— >" << endl;
}
else
{
if (find(operator_list.begin(), operator_list.end(), ch) != operator_list.end())
{
cout << "运算符 —— " << ch << endl;
}
else if (find(board_list.begin(), board_list.end(), ch) != board_list.end())
{
cout << "界符 —— " << ch << endl;
}
else
{
string errstr = string(1, ch);
errors(lines, 2, errstr);
}
}
getsym(str, index+1, lines);
return;
}
int printchar(char *str, int len)
{
for (int i = 0; i <= len; i++)
{
cout << str[i];
}
return 0;
}
void errors(int lines, int err_num, string errstr)
{
cout << "出错在" << lines << "行" << "原因是: " ;
switch (err_num)
{
case 0:
cout << "{ : 无法单独使用,需要联合 = 组成:= 才能一起使用 }" << endl;
break;
case 1:
cout << "{ : "<< errstr <<" 是错误的数字或者错误的标识符 }" << endl;
break;
case 2:
cout << "{ :" << errstr << " 符号未定义 }" << endl;
}
}
|