Pandas —— Python数据分析库
本文最后更新于:2020年9月21日 晚上
概览:Pandas介绍,Series与DataFrame的使用。
pandas
numpy能够帮助我们处理的是数值型的数据,当然在数据分析中除了数值型的数据还有好多其他类型的数据(字符串,时间序列),那么pandas就可以帮我们很好的处理除了数值型的其他数据!
pandas包含两个常用类:
- Series
- DataFrame
Series
类似于一位数组,由values以及index组成。
- index:相关的数据索引标签
- values:一组数据,ndarray类型。
创建
列表创建
1
2
3
4
5
6
7
8
9
10
11
12
13from pandas import DataFrame,Series
import pandas as pd
import numpy as np
Series(data=[1,2,3])
#
#结果:
#0 1
#1 2
#2 3
#dtype: int64
# 左边是index,右边是value用Numpy数组创建
1
Series(data=np.array([1,2,3]))用字典创建
1
2
3
4
5
6
7
8
9
10dic = { #字典中的key作为了Series的索引
'name':'bobo',
'salary':10000
}
Series(data=dic)
#
#name bobo
#salary 10000
#dtype: object索引与切片
- 默认形式的索引是0,1,2,3……这是隐式索引
- 显式索引:自定义索引。
1 | |
1 | |
常用方法
- head(n=5),tail():查看前/后n个元素
- unique():去重
- nunique():统计去重后元素的个数
- isnull() notnull() :判定元素是否为空,如果有空则返回True\false,否则返回false
- add() sub() mul() div()
算术运算
- 索引一致的元素进行算数运算否则补空。
1 | |
使用bool索引来取值
应用:过滤空值
1 | |
DataFrame
DataFrame是一个表格型的数据结构。DataFrame由按一定顺序排列的多列数据组成。设计初衷是将Series的使用场景从一维拓展到多维。DataFrame既有行索引,也有列索引。
DataFrame取出的行或者列都是一个Series。
行索引:index
列索引:columns
值:values
创建
ndarray创建
1
DataFrame(data=np.random.randint(0,100,size=(3,2)))字典创建
1
2
3
4
5
6dic = {
'names':['jay','bobo','tom'],
'score':[100,99,80]
}
df = DataFrame(data=dic)
df.index=['a','b','c'] #指定行索引字典创建数据源,字典的key作为列索引。
将某一列设置为行索引
df.set_index()
属性
- values:df的元素值
- index:行索引
- columns:列索引
- shape:形状。
信息
df.info()可以查看DF的具体信息。
df.describe()返回每列的数量、均值、方差等信息。
索引与切片
取列
df['names']
取行
df.loc['a']通过显示索引取行df.iloc[0]通过隐式索引取行df.loc[True,...,Flase]#通过布尔取得为真的行
取元素
df.iloc[1,1]通过隐式索引取元素,左行右列df.loc['a','names']通过显式索引取元素,左行右列
切行
df[0:2]切出前两行df。
切列
df.iloc[:,0:1]所有行,第0列。
丢失数据与处理
两种丢失数据:
None:对象类型np.nan即NaN:float类型
对象类型的空值是不可以直接参与运算的,而nan是可以直接参与运算。会自动将None转为NaN.
1 | |
np.isnull().any(axis=):可以查看每列是否为空等信息。any()常isnull()等搭配。
- dropna(axis=)`:可以直接将缺失的行或者列进行删除,0为行
fillna(value=):使用指定值做填充df.fillna(method='bfill',axis=0)使用临近值做填充。
使用均值填充数据
1 | |
使用中位数填充数据
- 如果序列中存在空值,则返回的中位数为空.故要去掉中位数。
1 | |
处理重复行
df.duplicated()查看是否有重复的数据。df.drop_duplicates(keep='last'):删除重复的行,keep表示保留最后一个重复的行。
删除行
df.drop(labels='',axis=0,inplace=True):指定行的标签。
日期转换与resample
pd.to_datetime(col)时间数据类型转换。
列的数据为str,形如2020-.1-12.
提取年:
pd.to_datetime(df['date'])dt.yeardata['2010-1':'2020-9']#对日期索引的切片,只有对日期可以这样
Pandas中的resample,重新采样,是对原样本重新处理的一个方法,是一个对常规时间序列数据重新采样和频率转换的便捷的方法。
resample('M'):获取了每一年每一个月df.resample('A'):获取每个年
级联
pd.concat((df1,df2),axis=0,join='outer')
- axis0表示按列,纵向级联。1表示按行横向级联。
join='outer'表示将所有的项进行级联(忽略匹配和不匹配),而inner表示只会将匹配的项级联到一起,不匹配的不级联。- 不匹配级联
- 不匹配指的是级联的维度的索引不一致。例如纵向级联时列索引不一致,横向级联时行索引不一致
- 有2种连接方式:
- 外连接:补NaN(默认模式)
- 内连接:只连接匹配的项
合并
级联是对表格做拼接,合并是对数据做合并
- merge与concat的区别在于,merge需要依据某一共同列来进行合并
- 使用pd.merge()合并时,会自动根据两者相同column名称的那一列,作为key来进行合并。
- 注意每一列元素的顺序不要求一致
1 | |
- left左表,right右表,on表示按照哪一列进行合并。
- how可取
left、right、outer、inner。- left:按照左边的列值来进行合并,类似于左连接
- outer使用并集的方式,inner使用交集的方式。
而当两表没有可以进行连接的列时,可使用left_on和right_on手动指定merge中左右两边的哪一列列作为连接的列。
1 | |
替换
单值替换
1
2
3df.replace(to_replace=10,value='ten') #替换所有值为10的值
df.replace(to_replace={3:10},value='ten') #将指定列中的相关数据进行替换,第3列的全部10进行替换。多值替换
- 列表替换:
to_replace=[] value=[] - 字典替换:
to_replace={to_replace:value,to_replace:value}
- 列表替换:
映射
创建一个映射关系列表,把values元素和一个特定的标签或者字符串绑定(给一个元素值提供不同的表现形式)。
实例:创建一个df,两列分别是姓名和薪资,然后给其名字起对应的英文名
1 | |

- map是Series的方法,只能被Series调用。
map充当运算工具
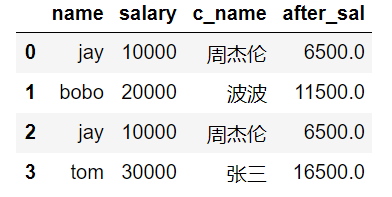
针对上述案例,超过3000部分的钱缴纳50%的税,计算每个人的税后薪资。
map()中传入一个接收一个参数的函数,来对每一个元素执行函数的操作。
1 | |
随机抽样
numpy.random.permutation(x): 随机排列一个序列,或者数组。- x是整数则随机排列
np.arange(x)。 - 如果x是多维数组,则沿其第一个坐标轴的索引随机排列数组。
1
2
3np.random.permutation(3)
# array([1, 0, 2])- x是整数则随机排列
take(indices, axis=0):沿着指定轴的给定索引返回按索引排序后的DataFrame。1
2#注意:indices只能跟隐式索引
df.take(indices=np.random.permutation(3),axis=1)分类处理
groupby(by='')来对指定的列进行分组。groupby(by='').groups来查看分组的情况。
高级数据聚合
使用groupby分组后,也可以使用transform和apply提供自定义函数实现更多的运算。
- df.groupby(‘item’)[‘price’].sum() <==> df.groupby(‘item’)[‘price’].apply(sum)
- transform和apply都会进行运算,在transform或者apply中传入函数即可
- transform和apply也可以传入一个lambda表达式
- apply和transform的区别:transform返回的是经过映射的结果,而apply返回的是没有经过映射的结果。
存取文件
1 | |
透视表-7
交叉表-7
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!